COBOL言語の「UNSTRING文」とは?文字分解を理解しよう! | 用語辞典
COBOL(コボル)言語の予約後UNSTRINGを使った命令文の書き方とは

COBOL(コボル)言語のUNSTRING文とは?
COBOL(コボル)には、文字列を任意の区切り文字で分解する、UNSTRINGという機能があります。文字列の分解は、例えばデリミタ(カンマ(,)など)で、区切りがあるレコードを記述しているCSVファイルなどを読み込んだとき、デリミタで区切った項目ごとにレコードを分解するときに使用します。
本記事では、UNSTRING文の基本的な使い方やルール、注意点などをご紹介します。
書き方:
UNSTRING [分解元のデータ] DELIMITED BY デリミタ(区切り文字)
INTO [分解したデータ保存項目]
TALLYING IN [分解数保存項目]
使用例:
以下にUNSTRING文を使用して、文字列を分解する簡単なサンプルを紹介します。
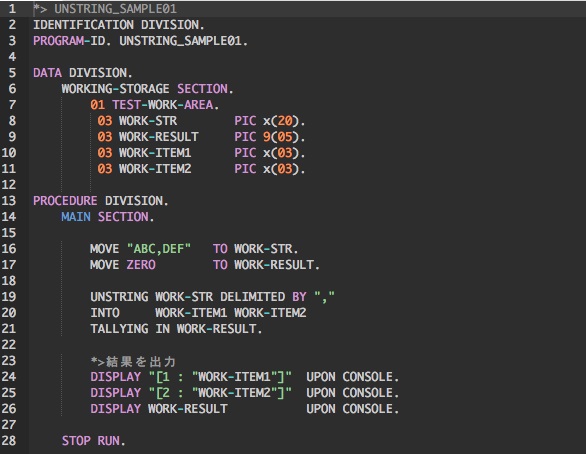
実行結果:
サンプルでは分解元の文字列を格納する項目、分解したデータを保存する項目、分解数を保持する項目を設定し、UNSTRING文で区切り文字としてカンマ(,)を指定しています。
分解後の文字列はINTO句で項目WORK-ITEM1、WORK-ITEM2に順番に保存されます。
最後にTALLYING INで分解数である2が返却されます。
DISPLAYで結果を確認すると、文字列が正しく分解されていることがわかります。
UNSTRING文のCOBOL(コボル)言語における基本事項やルールについて
- UNSTRING、分解元のデータ、DELIMITEDなどの各要素間における空白や改行有無は自由に設定できます。
- 分解数を保持するTALLYING INは省略可能です。
- 指定した受け取り数を超えて分解された場合は、保存できなかったデータは破棄されます。
- ",,"などカンマが連続している場合は、データ部で指定したサイズ分の空白文字列が保存されます。
- INTOの後に続く分解したデータ保存項目は、「英字」「英数字」「PICTURE句の文字列中に"P"を含まない数字」「日本語」のいずれかを指定し、50項目までに制限されます。
COBOL(コボル)言語のUNSTRING文を扱う上での注意点
UNSTRING文は文字列を分解するのに便利な命令文ですが、注意しておきたい点があります。
注意点1:
分解した文字列はINTO句で指定した項目へ順番に保存されますが、基本事項やルールで説明したとおり、項目の数を超えて文字列が分解されてしまった場合、保存できなかった分のデータは破棄されてしまいます。
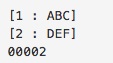
例えば、以下のサンプルのように文字列"ABC,DEF,GHI,JKL"をカンマ区切りで分解し、INTO句で分解したデータの保存項目を2つしか指定しなかった場合、"GHI,JKL"は破棄されてしまいます。
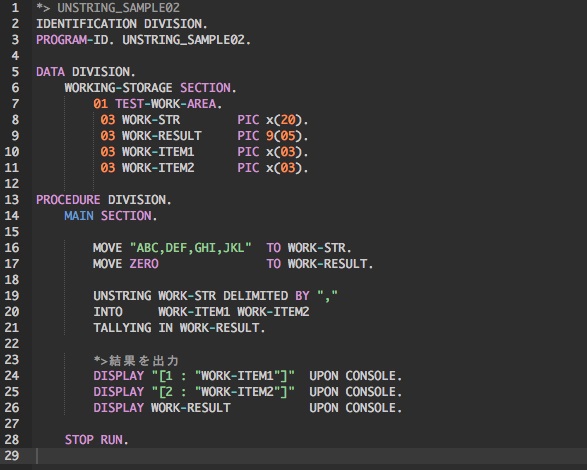
注意点2:
カンマ(,)が連続している箇所は、1つの空白文字列として分解されるので注意が必要です。
以下は、文字列"ABC"と"DEF"の間にカンマ(,)が連続しているため、5種類の文字列として分解されます。
[ABC,,DEF,GHI,JKL]→[ABC][空白][DEF][GHL][JKL]
UNSTRING文を使ったCOBOL(コボル)プログラムの活用法
文字列を分解する場合、分解対象のデリミタが1つとは限らない場合があります。例えば、カンマ(,)以外にもコロン(;)がある場合、デリミタごとにUNSTRING文を使うのは面倒です。
そのような場合にはUNSTRING文でDELIMTED BY 区切り文字の後にORを指定して、続けて区切り文字を使用する方法も可能です。
以下に、カンマ(,)とコロン(;)が含まれる文字列を分解する簡単なサンプルを紹介します。
- IDENTIFICATION DIVISION.
- PROGRAM-ID. UNSTRING_SAMPLE03.
- ENVIRONMENT DIVISION.
- CONFIGURATION SECTION.
- DATA DIVISION.
- WORKING-STORAGE SECTION.
- 01 TEST-WORK-AREA.
- 03 WORK-STR PIC x(20).
- 03 WORK-RESULT PIC 9(05).
- 03 WORK-ITEM PIC x(03) OCCURS 4.
- PROCEDURE DIVISION.
- MAIN SECTION.
- MOVE "ABC,DEF;GHI,JKL" TO WORK-STR.
- MOVE ZERO TO WORK-RESULT.
- UNSTRING WORK-STR DELIMITED BY "," OR ";"
- INTO WORK-ITEM(1) WORK-ITEM(2)
- WORK-ITEM(3) WORK-ITEM(4)
- TALLYING IN WORK-RESULT.
- *>結果を出力
- DISPLAY "[1 : "WORK-ITEM(1)"]" UPON CONSOLE.
- DISPLAY "[2 : "WORK-ITEM(2)"]" UPON CONSOLE.
- DISPLAY "[3 : "WORK-ITEM(3)"]" UPON CONSOLE.
- DISPLAY "[4 : "WORK-ITEM(4)"]" UPON CONSOLE.
- DISPLAY WORK-RESULT UPON CONSOLE.
- STOP RUN.
実行結果
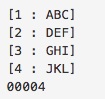
サンプルではカンマ(,)とセミコロン(;)を含む文字列"ABC,DEF;GHI,JKL"を設定してUNSTRING文で分解しています。
分解時にDELIMITED BY "デリミタ1" OR "デリミタ2"で、カンマ(,)とセミコロン(;)をそれぞれ指定すれば、2つの区切りで文字列を分解し、INTO句でデータ保存項目に順番に分解した文字列を保存することが可能です。
また、分解した文字列が多くなる場合は、OCCURS句を指定して配列のデータ項目を使用すれば、記述するコード量を減らすことができて可読性も上がります。
※配列を使用するOCCURS句については、別の記事で詳しく説明いたします。
この記事を読んだ人は、こちらの記事も読んでいます
あなたのCOBOL技術を活かしませんか?
COBOL入門のカテゴリー
取引企業様 募集中
1. 優良社員が多数在籍しています
2. 即日派遣、又は請負います
3. 安心価格で請負います
4. 同時、協力会社募集中です
COBOL技術者 募集
1. 正社員
2. 契約社員
3. 個人事業主
などの
求人情報
が閲覧できます。
COBOL魂
目指せ!COBOLダントツ一番企業。
創業当初の話や理念が閲覧できます。
COBOL入門
COBOLとは、どのようなプログラミング言語なのか、初心者にもわかりやすく、文法の例をあげて解説してます。
COBOL入門の人気記事
- COBOL言語とは?プログラムの書き方やルールを解説!|基礎ガイド
- 【COBOL言語】条件分岐処理の代名詞「IF文」について知ろう|用語辞典
- COBOL言語の「MOVE文」とは?転記のルールをご紹介します|用語辞典
- COBOL言語の「STRING文」とは?文字連結の基礎知識と注意点|用語辞典
- 多枝分岐ってなに?COBOL言語の「EVALUATE文」を知ろう!|用語辞典
- COBOL言語の「PICTURE句」とは?基本事項を解説します!|用語辞典
- COBOL言語で計算処理をするなら「COMPUTE文」|用語辞典
- COBOL言語の「REDEFINES句」とは?使い方を確認しよう!|用語辞典
- 覚えておけば楽ができる?COBOL言語の「COPY文」の使い方|用語辞典
- COBOL言語の文字列操作のパターンを理解しよう!|基礎ガイド
- COBOL言語の初期化処理に重宝する「INITIALIZE文」とは?|用語辞典
- COBOL言語の「LOW-VALUE」の使い方について理解しよう!|基礎ガイド
- COBOL言語の「OCCURS句」について知ろう!学ぶべき基本とは|用語辞典
- COBOL言語初心者も安心! 難解「CALL文」をスッキリ解決|用語辞典
- COBOL言語の「PERFORM文」とは。実行制御について解説!|用語辞典
- COBOL言語の繰り返し処理のパターンを理解しよう!|基礎ガイド
- COBOL言語の「定数」の種類と使い方について理解しよう!|用語辞典
- COBOLのDBアクセスパターンを学ぼう!「FETCH」|応用ガイド
- COBOL言語の「DISPLAY文」は、ディスプレイ出力の為にある|用語辞典
- COBOL言語の「VARYING句」は便利?使用方法を学びましょう|用語辞典

