COBOLのSQLCODEを利用したエラーハンドリングとは?|応用ガイド
COBOL(コボル)言語のDB操作の結果を判断するSQLCODEとは?

COBOL(コボル)言語のDB操作の結果を判断する「SQLCODE」とは?
一般的なDBはリレーショナル型データベース(RDB)を指します。RDBは、問い合わせ言語(SQL)を利用してデータにアクセスを行います。これらはDBアクセスを学ぶ上での共通事項です。
今回ご紹介するSQLCODEはこれらDBアクセスで利用されるSQLの処理結果を持つ変数で、処理が正常終了しているのか、異常終了しているのか、異常終了している場合はどのようなエラーが発生しているのかを値として持ちます。では、SQLCODEの値の意味とその書き方について見ていきましょう。
書き方:
SQLCODE = 0 ・・処理正常終了
SQLCODE = 100 ・・FETCH処理時、該当データなし
SQLCODE > 0 ・・警告
SQLCODE < 0 ・・処理異常終了
COBOL(コボル)言語のDBアクセスの処理構成と「SQLCODE」との関係
DBアクセスの基本的な処理構成とSQLCODEとの関係について見ていきましょう。
[基本的な処理構成]
1.ホスト変数の定義、2.共通領域の定義、3.データベース接続、4.データベースアクセス
各処理で実施する処理内容は以下の通りです。
1.ホスト変数の定義
COBOL、DB間のデータ連携用の変数を定義します。この変数を利用してDBから取得したデータをCOBOLで加工、編集する事ができるようになります。
2.共通領域の定義
SQL実行時に出るエラー、警告及びステータス情報を格納するための領域を定義します。ここに最新のSQLの実行結果が反映される事になります。今回ご紹介しているSQLCODEもこちらの定義に含まれています。
3.データベース接続
ユーザID、パスワードを指定し、DBと接続します。
4.データベースアクセス
DBの操作(検索、追加、更新、削除など)を行います。今回ご紹介するSQLCODEはこれらDB操作の後に記述し、処理の正常・異常を判断した後、異常終了時は適切なエラーハンドリング処理につなげていく事になります。
では基本的な処理構成について記述したサンプルプログラム(使用例1)を用意しましたので、その書き方について見ていきましょう。
使用例1:
※今回のDBMSは、オープンソースの「PostgreSQL」を使用しています。
※USERNAME、PASSWORDはご自身の環境に合わせて指定ください。
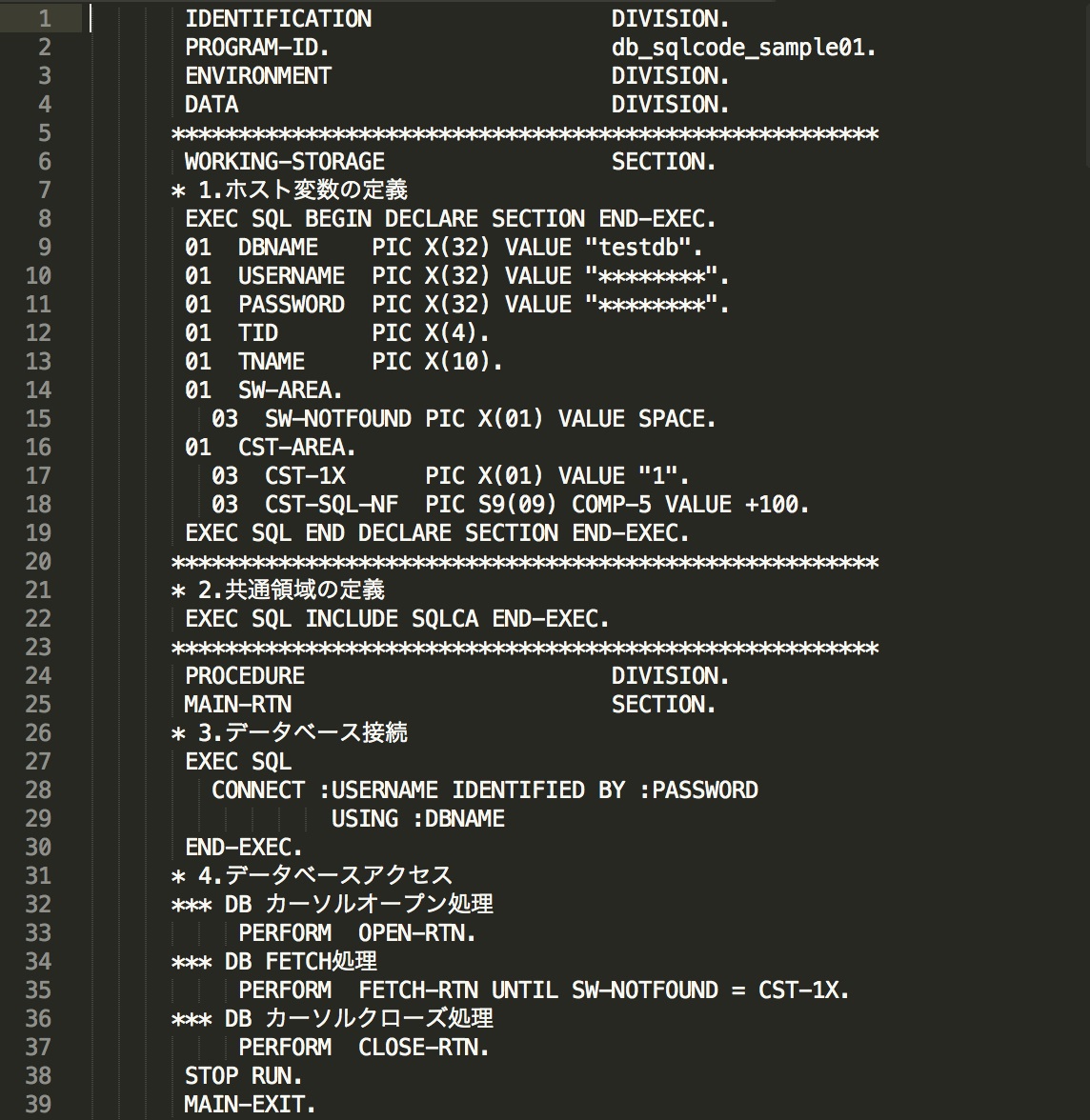
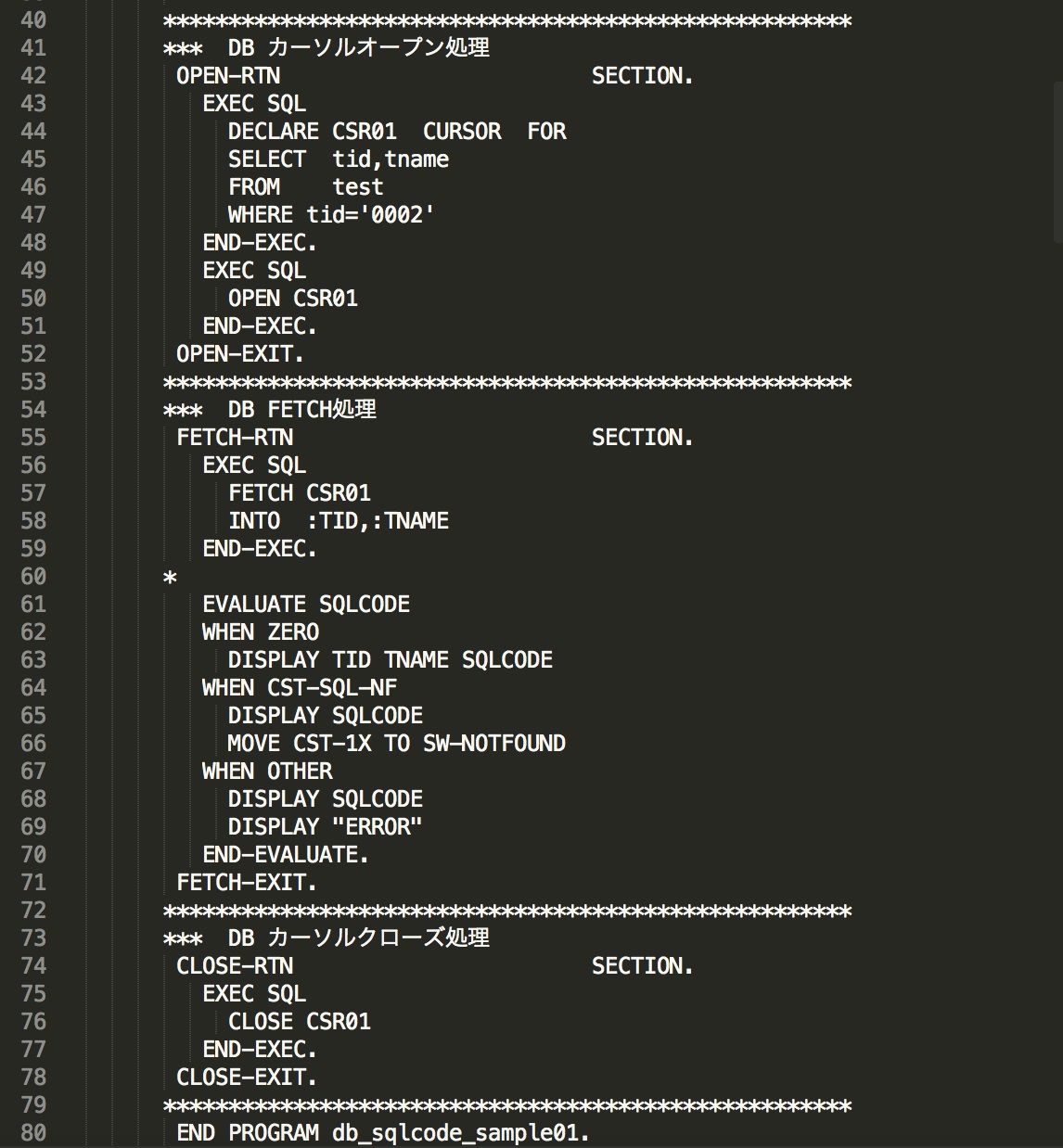
使用例1は、DB(testdb)に、ユーザID、パスワードを指定して接続し、テーブル「test」の列名「tidが'0002'」のデータを検索するプログラムです。検索後にSQLCODEが0(正常終了)か、100(該当データなし)か、それ以外(異常終了)かを判断し、後続処理を実施している事がご確認いただけるかと思います。
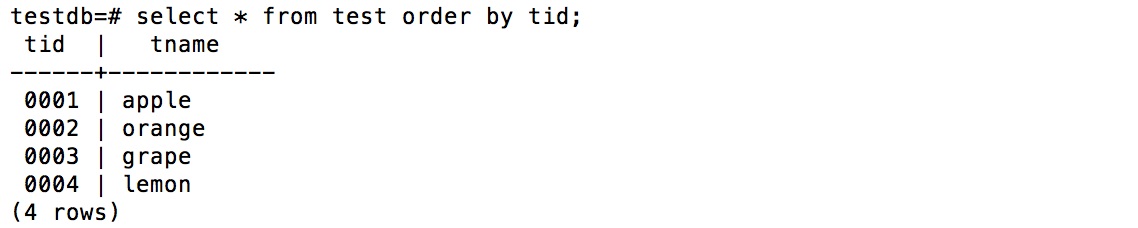
テーブル(test):処理実行前

実行結果:

COBOL(コボル)言語の「SQLCODE」の応用的な使い方
DBアクセスとSQLCODEの基本的な処理構成と書き方について理解いただけたでしょうか。今度は、応用的な使い方について考えていきましょう。
先ほどご紹介したサンプルプログラムは、SQLCODE=0、100のケースを確認しましたが、今回はSQLCODE<0になるケースについて考えてみましょう。SQLCODE<0は処理が異常終了するケースですので、通常はエラーメッセージ等を出力し、処理を中断させるなどしますが、意図的に処理を進めるケースもあります。
応用編では、このケースとしてDBのレコード新設時にキー重複が発生した場合について考えてみましょう。具体的なサンプルプログラム(使用例2)を用意しましたので、しっかり内容を理解して実際のプログラム作成に活用いただければと思います。
使用例2:
- IDENTIFICATION DIVISION.
- PROGRAM-ID. db_sqlcode_sample02.
- ENVIRONMENT DIVISION.
- DATA DIVISION.
- WORKING-STORAGE SECTION.
- * 1.ホスト変数の定義
- EXEC SQL BEGIN DECLARE SECTION END-EXEC.
- 01 DBNAME PIC X(32) VALUE "testdb".
- 01 USERNAME PIC X(32) VALUE "********".
- 01 PASSWORD PIC X(32) VALUE "********".
- EXEC SQL END DECLARE SECTION END-EXEC.
- * 2.共通領域の定義
- EXEC SQL INCLUDE SQLCA END-EXEC.
- PROCEDURE DIVISION.
- * 3.データベース接続
- EXEC SQL
- CONNECT :USERNAME IDENTIFIED BY :PASSWORD
- USING :DBNAME
- END-EXEC.
- * 4.データベースアクセス
- * 4-1.INSERT1 キー重複
- EXEC SQL
- INSERT INTO test
- (tid,tname)
- VALUES ('0002','grape')
- END-EXEC.
- EVALUATE SQLCODE
- WHEN ZERO
- DISPLAY SQLCODE
- EXEC SQL
- COMMIT
- END-EXEC
- WHEN OTHER
- DISPLAY SQLCODE "," SQLSTATE
- DISPLAY "ERROR"
- EXEC SQL
- ROLLBACK
- END-EXEC
- END-EVALUATE.
- * 4-1.INSERT2 正常
- EXEC SQL
- INSERT INTO test
- (tid,tname)
- VALUES ('0003','grape')
- END-EXEC.
- EVALUATE SQLCODE
- WHEN ZERO
- DISPLAY SQLCODE
- EXEC SQL
- COMMIT
- END-EXEC
- WHEN OTHER
- DISPLAY SQLCODE "," SQLSTATE
- DISPLAY "ERROR"
- EXEC SQL
- ROLLBACK
- END-EXEC
- END-EVALUATE.
- STOP RUN.
- END PROGRAM db_sqlcode_sample02.
使用例2は、テーブル「test」に2レコードデータを新設する処理になります(テーブル「test」の主キーは列名「tid」)。ただし「tid='0002'」の場合は既にデータが存在しているためレコードが新設できずSQLCODEも<0で返っています。一方「tid='0003'」の場合はデータが存在しないためレコードが新設でき、SQLCODEも0で正常終了している事がご確認いただけるかと思います。
テーブル(test):処理実行前

実行結果:

テーブル(test):処理実行後
練習問題
最後に練習問題にチャレンジしてみましょう。
問)
使用例1では、FETCH処理後にSQLCODEの判断処理を入れましたが、その他にSQLCODEの判断処理を入れるべきところはないでしょうか?実際にプログラムも修正して確認してみましょう。
答え)
SQLの操作を行っている箇所全てにSQLCODEによる判断処理を入れるべき、となります。具体的にはカーソルのオープン、クローズ処理後になります。
ただし、実際にプログラムに組み込む際には同じような判断処理になる事が多いため、プログラムのコーディングやテスト、プログラムの品質や保守性を考えると、共通処理として定義しておく事が望ましいでしょう。
この記事を読んだ人は、こちらの記事も読んでいます
あなたのCOBOL技術を活かしませんか?
COBOL入門のカテゴリー
取引企業様 募集中
1. 優良社員が多数在籍しています
2. 即日派遣、又は請負います
3. 安心価格で請負います
4. 同時、協力会社募集中です
COBOL技術者 募集
1. 正社員
2. 契約社員
3. 個人事業主
などの
求人情報
が閲覧できます。
COBOL魂
目指せ!COBOLダントツ一番企業。
創業当初の話や理念が閲覧できます。
COBOL入門
COBOLとは、どのようなプログラミング言語なのか、初心者にもわかりやすく、文法の例をあげて解説してます。
COBOL入門の人気記事
- COBOL言語とは?プログラムの書き方やルールを解説!|基礎ガイド
- 【COBOL言語】条件分岐処理の代名詞「IF文」について知ろう|用語辞典
- COBOL言語の「MOVE文」とは?転記のルールをご紹介します|用語辞典
- COBOL言語の「STRING文」とは?文字連結の基礎知識と注意点|用語辞典
- 多枝分岐ってなに?COBOL言語の「EVALUATE文」を知ろう!|用語辞典
- COBOL言語の「PICTURE句」とは?基本事項を解説します!|用語辞典
- COBOL言語で計算処理をするなら「COMPUTE文」|用語辞典
- COBOL言語の「REDEFINES句」とは?使い方を確認しよう!|用語辞典
- 覚えておけば楽ができる?COBOL言語の「COPY文」の使い方|用語辞典
- COBOL言語の文字列操作のパターンを理解しよう!|基礎ガイド
- COBOL言語の初期化処理に重宝する「INITIALIZE文」とは?|用語辞典
- COBOL言語の「LOW-VALUE」の使い方について理解しよう!|基礎ガイド
- COBOL言語の「OCCURS句」について知ろう!学ぶべき基本とは|用語辞典
- COBOL言語初心者も安心! 難解「CALL文」をスッキリ解決|用語辞典
- COBOL言語の「PERFORM文」とは。実行制御について解説!|用語辞典
- COBOL言語の繰り返し処理のパターンを理解しよう!|基礎ガイド
- COBOL言語の「定数」の種類と使い方について理解しよう!|用語辞典
- COBOLのDBアクセスパターンを学ぼう!「FETCH」|応用ガイド
- COBOL言語の「DISPLAY文」は、ディスプレイ出力の為にある|用語辞典
- COBOL言語の「VARYING句」は便利?使用方法を学びましょう|用語辞典

